python을 이용한 대학교 내의 동영상 강의 다운로드로 크롤링 연습하기
빅데이터 강의시간의 크롤링 수업을 복습하기 위해 제작.
전체 프로세스는 로그인 하기-> 강의 목록 가져오기 -> 선택한 강의의 동영상 목록 가져오기 -> 동영상 다운로드
1. 로그인하기
1.1 로그인 요청
아이디와 비밀번호를 입력하여 로그인 버틀을 누르면
브라우저는 index.php에 대해 username(아이디)와 password(비밀번호)의 form data를 이용해 요청을 보낸다.
파이썬에서는 requests 라이브러리를 이용하면 request를 보낼 수 있다.
response이 이캠퍼스 주소일 경우 while문을 빠져 나오고,
그렇지 않으면 올바른 아이디,비밀번호 입력을 받을 때까지 반복한다.
import requests
from bs4 import BeautifulSoup
import youtube_dl
import os
session = requests.session()
url = "https://ecampus.changwon.ac.kr/login/index.php"
while(True):
id = input("id: ")
password = input("password: ")
data = {
"username": id,
"password": password
}
response = session.post(url, data=data)
if (response.url == 'https://ecampus.changwon.ac.kr/'):
break
print("아이디 또는 패스워드가 잘못 입력되었습니다.")
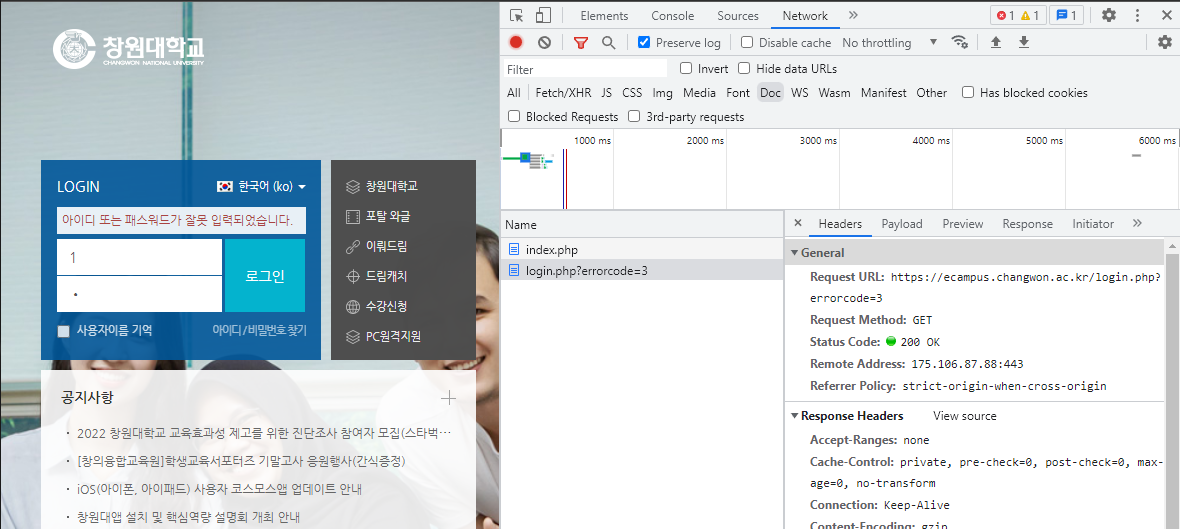
1.2 로그인 실패
아이디 또는 패스워드의 잘못된 입력으로 패스워드 입력이 실패하면 login.php?errorcode=3를 response으로 받는다.
1.3 로그인 성공
올바른 아이디, 비밀번호 입력을 통해 로그인에 성공하면 이캠퍼스의 주소를 response으로 받는다.
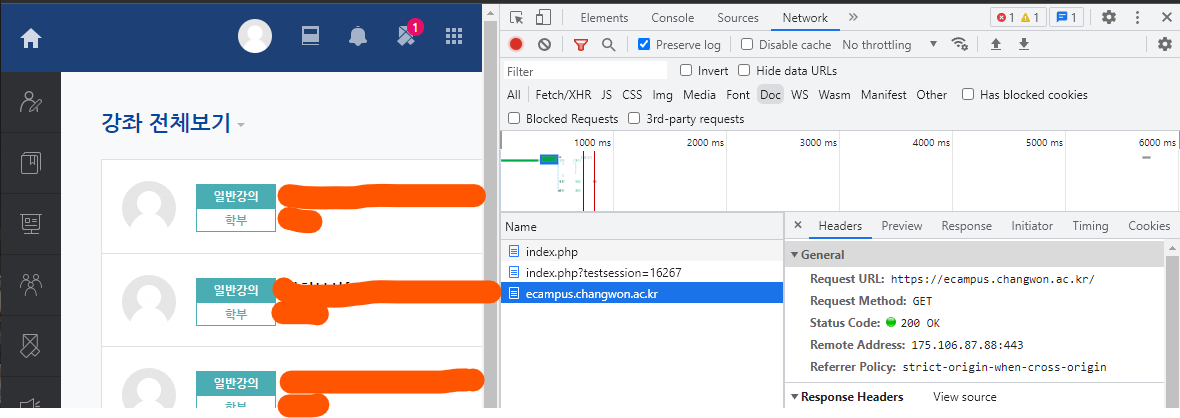
2. 강의 목록찾기
로그인을 통해 이캠퍼스에 접속하였다면, 각 강의의 주소와 강의 제목을 가져온다.
각 강의는 <div class="course_box">로 감싸져 있으며
그 하위의 <a>에 강의주소가 있고, <h3>에 강의제목이 있다.
url = "https://ecampus.changwon.ac.kr/"
response = session.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
list_course = []
for course in soup.find_all("div", "course_box"):
course_title = course.select(".course-title h3")[0].contents[0] //강의제목
course_href = course.find("a")["href"] //강의주소
list_course.append([course_title, course_href])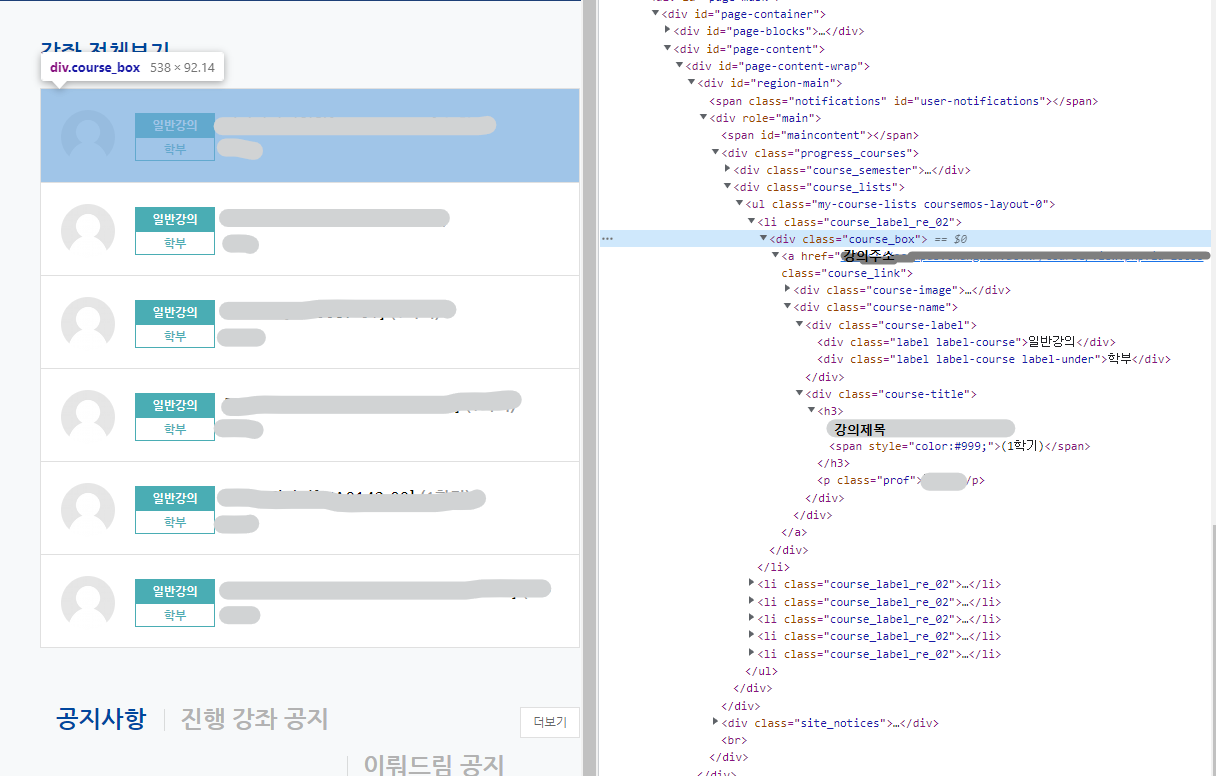
3. 강의 페이지내의 동영상 주소 찾기
강의 페이지내의 동영상 주소를 가지고 있는 요소는 각각의 <li>요소 하위에 있고 이 li는 고유한 동영상 id를 가지고 있다.
이 동영상 id를 viewer.php에 넘겨주면 동영상 페이지가 나오고
페이지 내의 <source>요소의 src속성에 m3u8 주소가 들어있다.
response = session.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
list_video = []
for tag in soup.find_all("li", "modtype_vod"):
# print(tag.select(".instancename")[0].text[:-4])
temp_url = 'https://ecampus.changwon.ac.kr/mod/vod/viewer.php?id=' + \
tag['id'][-6:] // 동영상 페이지 주소
temp_response = session.get(temp_url)
temp_response.raise_for_status()
temp_soup = BeautifulSoup(temp_response.text, "html.parser")
m3u8_url = temp_soup.find("source")["src"] //동영상 스트리밍 주소
title = temp_soup.select("#vod_header h1")[0].contents[0].strip()
list_video.append([title, m3u8_url])

4. m3u8 동영상 다운로드
각각 동영상의 m3u8 주소를 얻어 모두 list_video에 저장했다면
마지막으로 동영상을 다운로드 받으면 된다.
youtube_dl을 이용하여 동양상을 다운로드 받아 download폴더 내에 "동영상강의제목.mp4"파일으로 저장한다
for title, url in list_video:
output_dir = os.path.join('./download', title+'.%(ext)s')
ydl_opt = {'outtmpl': output_dir}
with youtube_dl.YoutubeDL(ydl_opt) as ydl:
ydl.download([m3u8_url, ])
print("다운로드가 완료되었습니다.")※다운로드가 제대로 되지 않는다면 ffmpeg를 설치하거나 ffmpeg.exe파일을 python파일과 같은 폴더 내에 위치시켜 보세요.
※ 강의 동영상은 교수님의 소중한 저작권이므로 무단으로 배포하거나 상업적으로 이용하는 등 악용하면 안됩니다.
이하는 전체코드
import requests
from bs4 import BeautifulSoup
import youtube_dl
import os
# 로그인
session = requests.session()
url = "https://ecampus.changwon.ac.kr/login/index.php"
while(True):
id = input("id: ")
password = input("password: ")
data = {
"username": id,
"password": password
}
response = session.post(url, data=data)
if (response.url == 'https://ecampus.changwon.ac.kr/'):
break
print("아이디 또는 패스워드가 잘못 입력되었습니다.")
# 강의 목록 찾기
url = "https://ecampus.changwon.ac.kr/"
response = session.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
list_course = []
for course in soup.find_all("div", "course_box"):
course_title = course.select(".course-title h3")[0].contents[0]
course_href = course.find("a")["href"]
list_course.append([course_title, course_href])
while(True):
print("번호 강의명")
for idx, course in enumerate(list_course):
print(idx, course[0])
while(True):
idx = int(input("다운로드 받을 강의의 번호를 입력하세요 : "))
if(idx > 0 and idx < len(list_course)):
break
# 해당 강의의 동영상 목록 찾기
url = list_course[idx][1]
response = session.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
list_video = []
for tag in soup.find_all("li", "modtype_vod"):
# print(tag.select(".instancename")[0].text[:-4])
temp_url = 'https://ecampus.changwon.ac.kr/mod/vod/viewer.php?id=' + \
tag['id'][-6:]
temp_response = session.get(temp_url)
temp_response.raise_for_status()
temp_soup = BeautifulSoup(temp_response.text, "html.parser")
m3u8_url = temp_soup.find("source")["src"]
title = temp_soup.select("#vod_header h1")[0].contents[0].strip()
list_video.append([title, m3u8_url])
print("동영상 목록")
for title, url in list_video:
print(title)
print("총 ", len(list_video), "개의 동영상이 있습니다. ")
# 동영상 다운로드
if(len(list_video)) > 0:
bool_download = int(input("다운로드 하시겠습니까? (yes:0, no:1)"))
if bool_download == 0:
for title, url in list_video:
output_dir = os.path.join('./download', title+'.%(ext)s')
ydl_opt = {'outtmpl': output_dir}
with youtube_dl.YoutubeDL(ydl_opt) as ydl:
ydl.download([m3u8_url, ])
print("다운로드가 완료되었습니다.")
bool_continue = int(input("다른 강의를 다운로드 하시겠습니까? (yes:0, no:1)"))
if(bool_continue == 1):
break